 琼公网安备46010602001577号
琼公网安备46010602001577号
Newstar CTF 2025 Week 2 Re方向 Write Up
采一朵花,送给艾达(1)
打开可以发现 IDA 无法将程序反编译为伪代码了
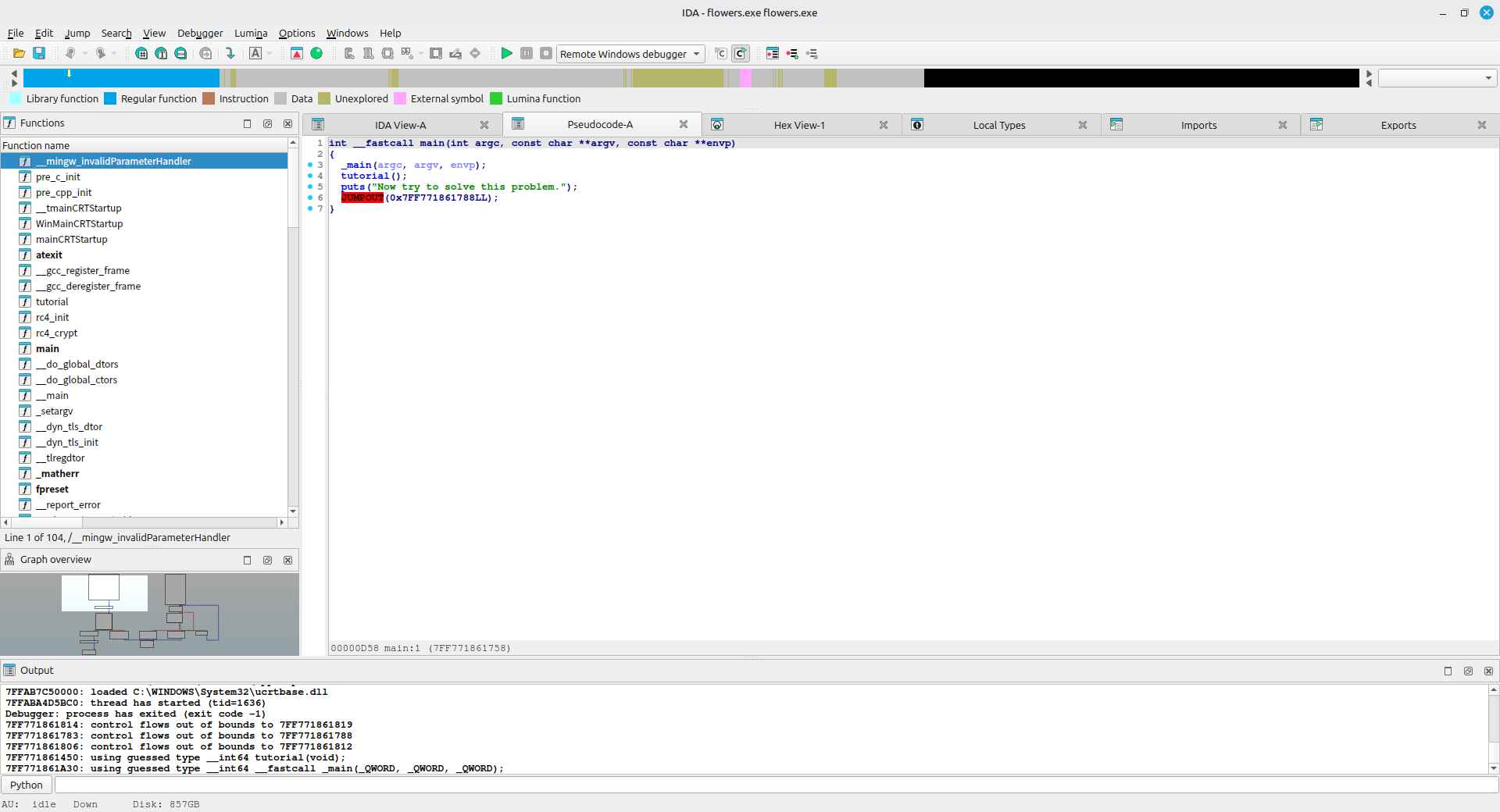
查看字符串和汇编可以发现程序添加了花指令
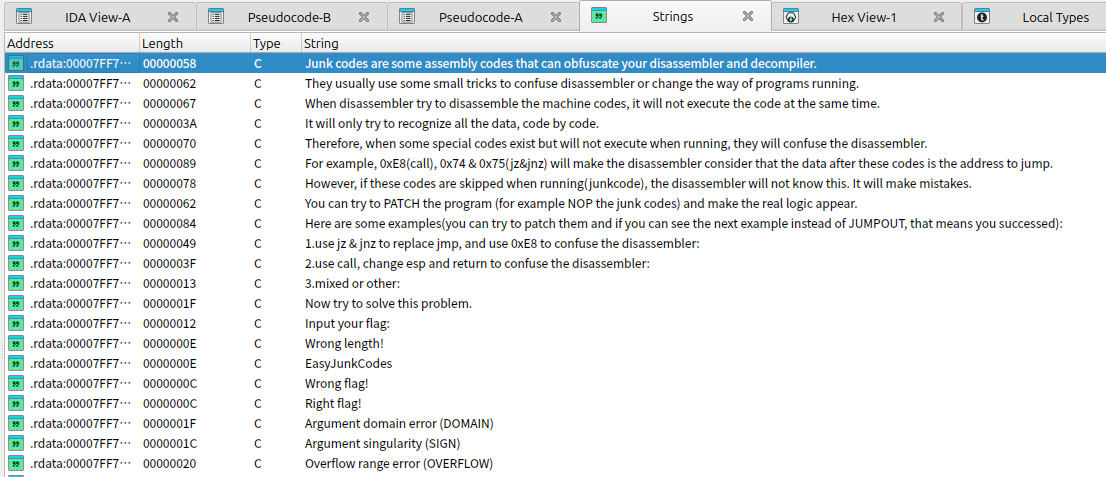
花指令是企图隐藏掉不想被逆向工程的代码块 (或其它功能) 的一种方法, 在真实代码中插入一些垃圾代码的同时还保证原有程序的正确执行, 而程序无法很好地反编译, 难以理解程序内容, 达到混淆视听的效果。
花指令通常用于加大静态分析的难度。
有关花指令可以看这几篇文章:
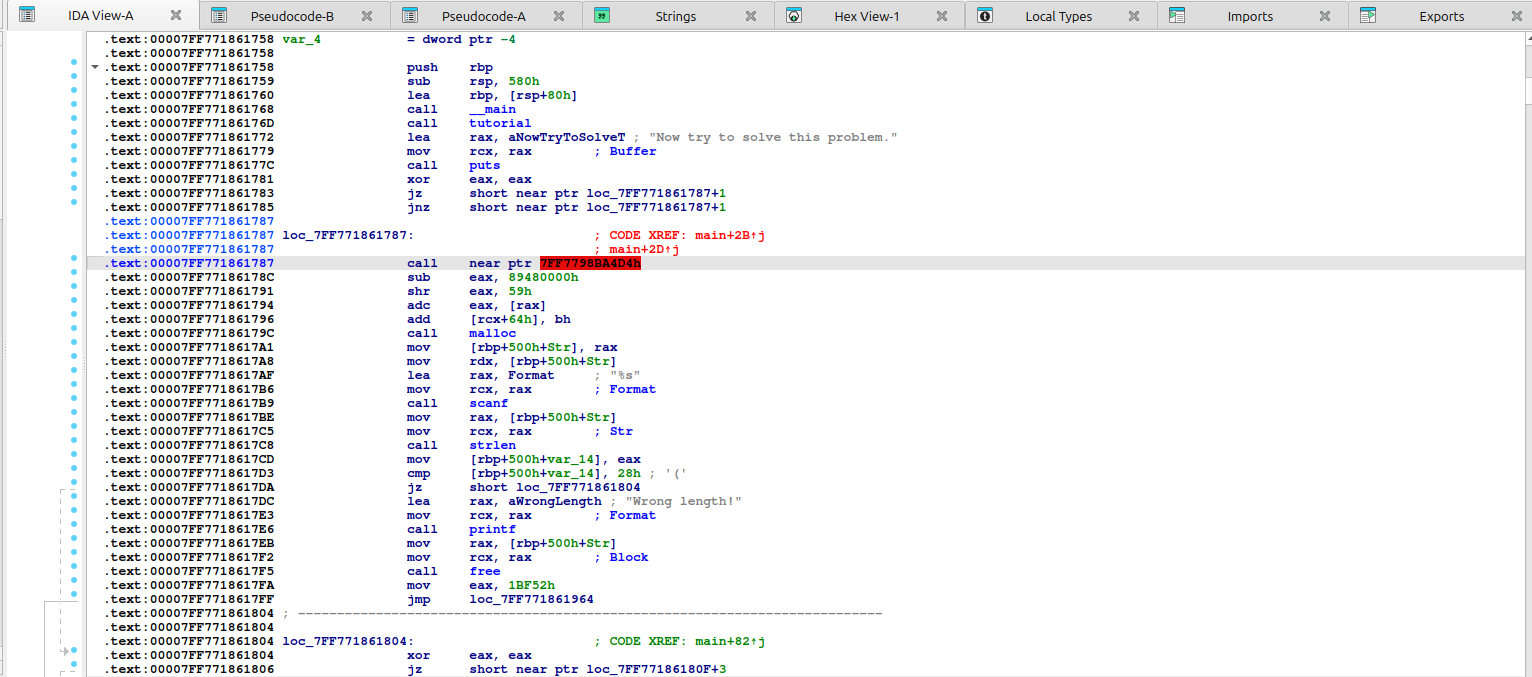
如果对汇编不熟悉,手动去花可能会有点麻烦,这里我们可以使用动调来去花

着重看这几个函数,在汇编处的类似的地方下断点:
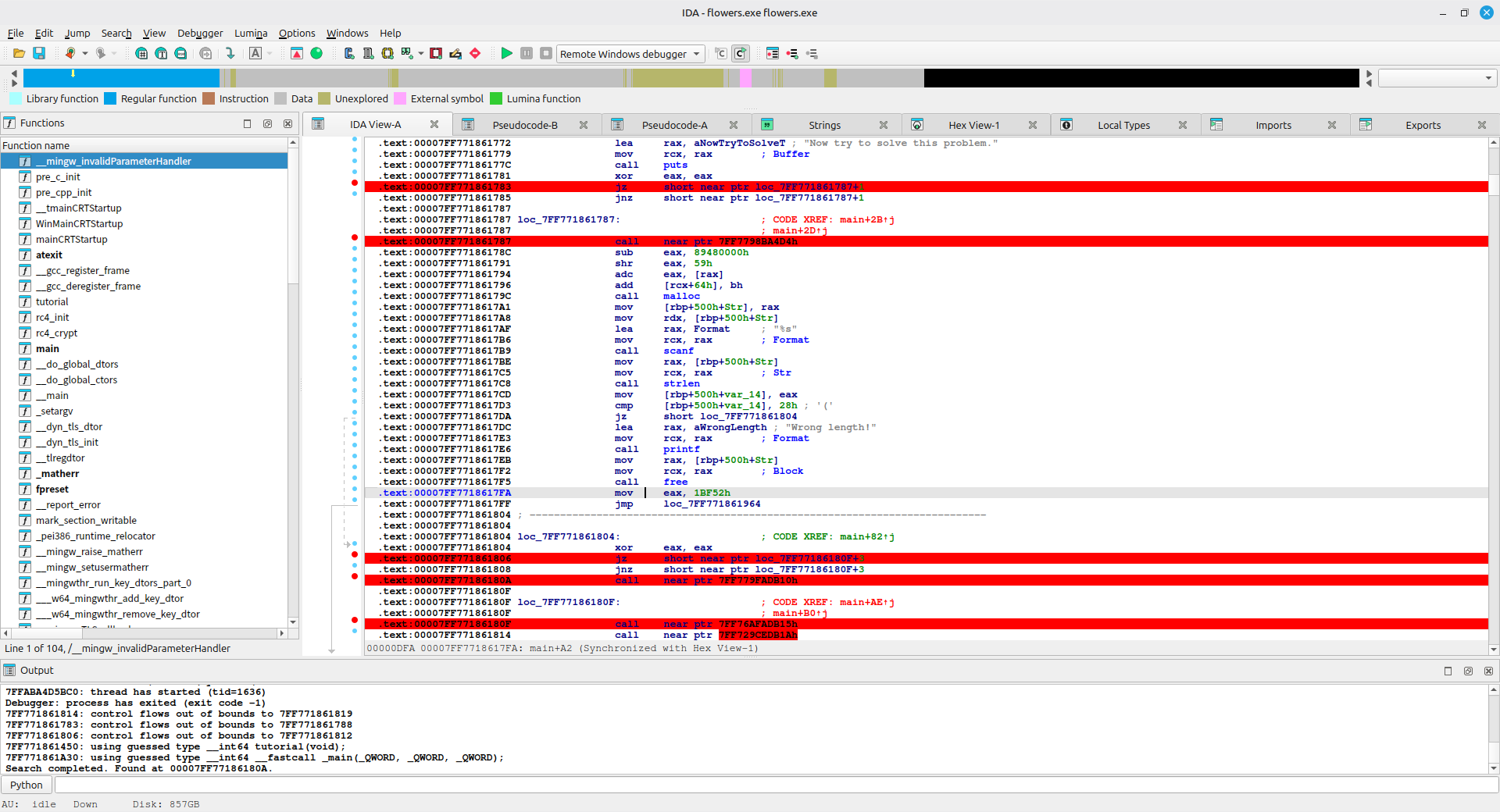
按 F7 步入,IDA 会提示“是否要在RIP处直接创建指令?”
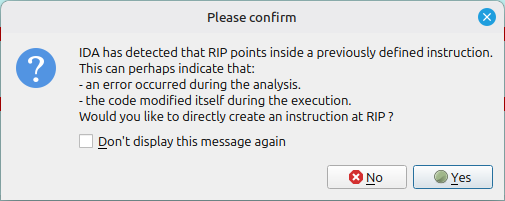
点击是,再按 F5 会发现有一些汇编能够被反编译了
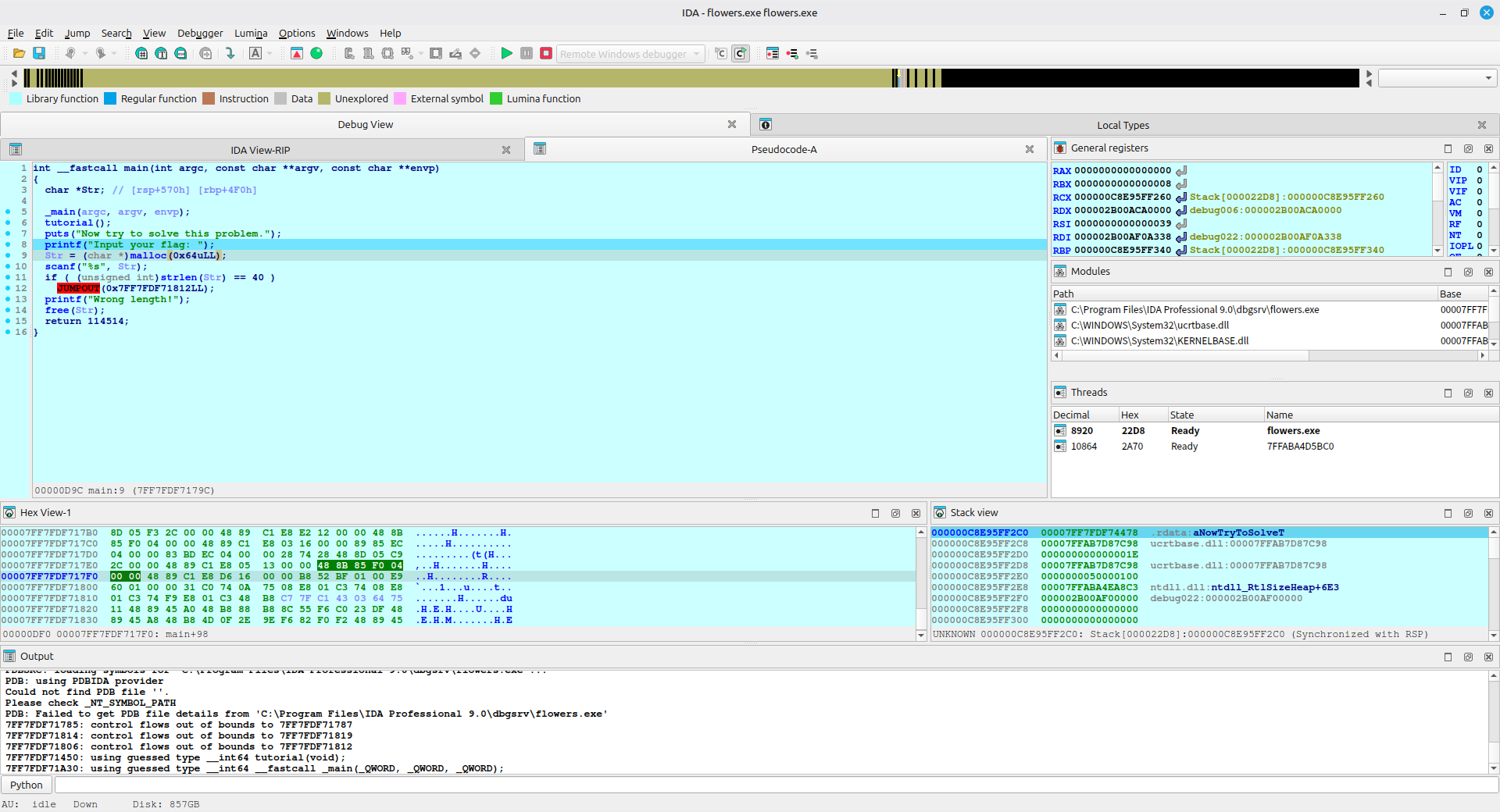
继续按 F7 步入,IDA 会一步步重建,最后就可以看到正常反编译的情况了
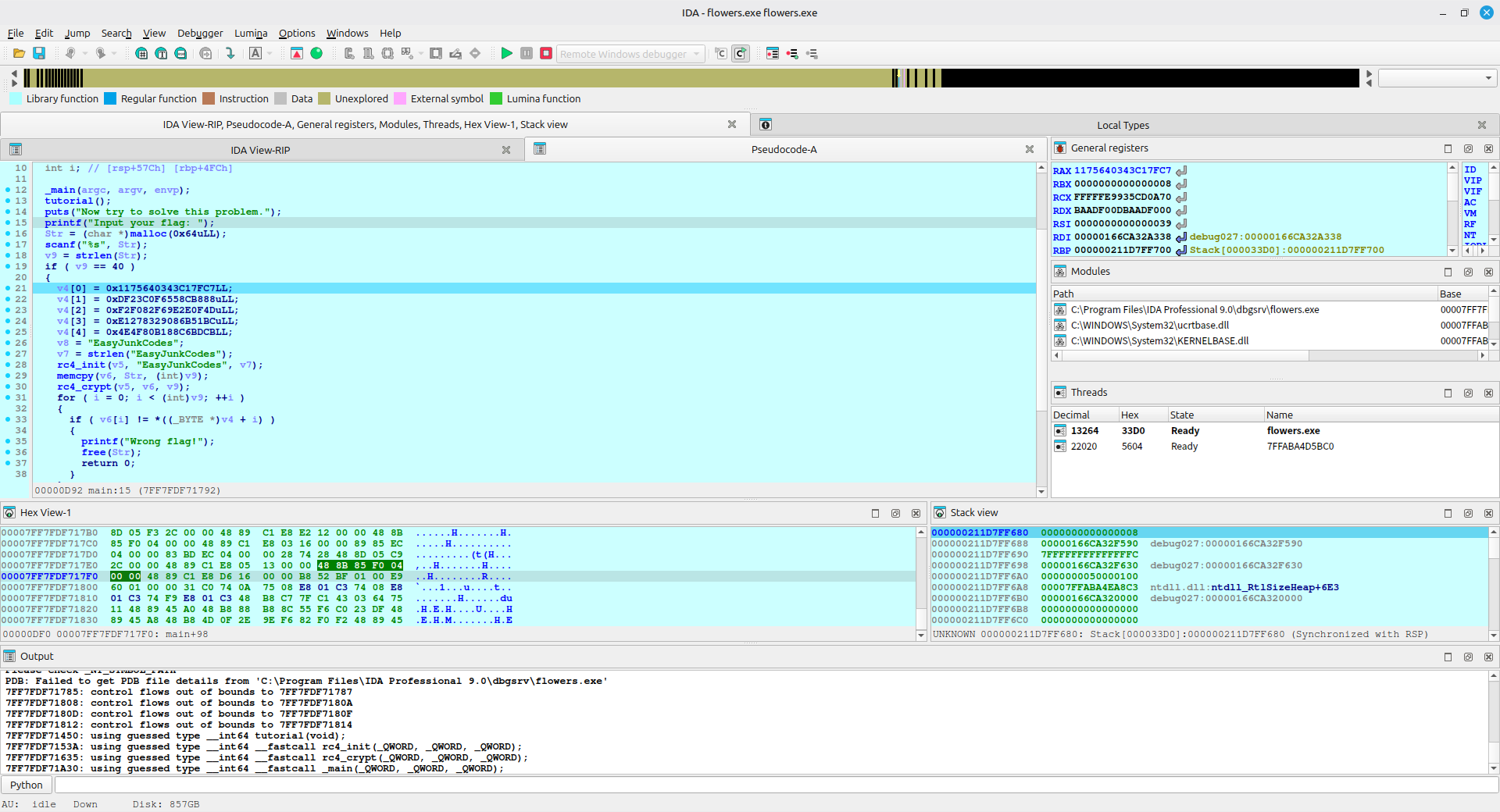
这里使用了 RC4 加密,有密文和密钥,但是直接使用 Cyberchef 无法解出正常的 flag,可以猜测这是非标准的 RC4 加密
点击 rc4_init 查看,可以发现 IDA 也无法反编译
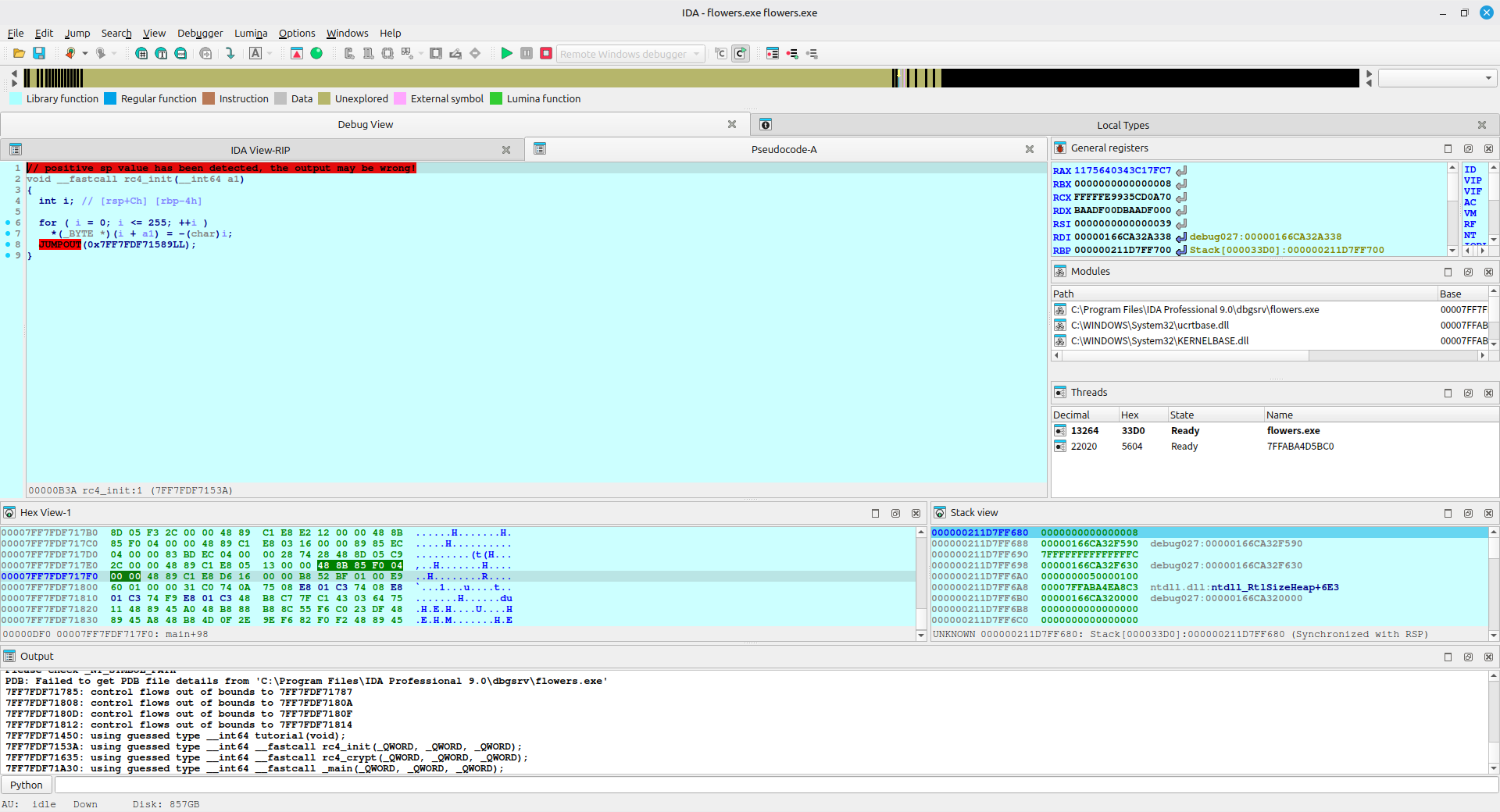
用同样的手法,在汇编中那几句类似的语句下断点,然后用动调一步步让 IDA 重建
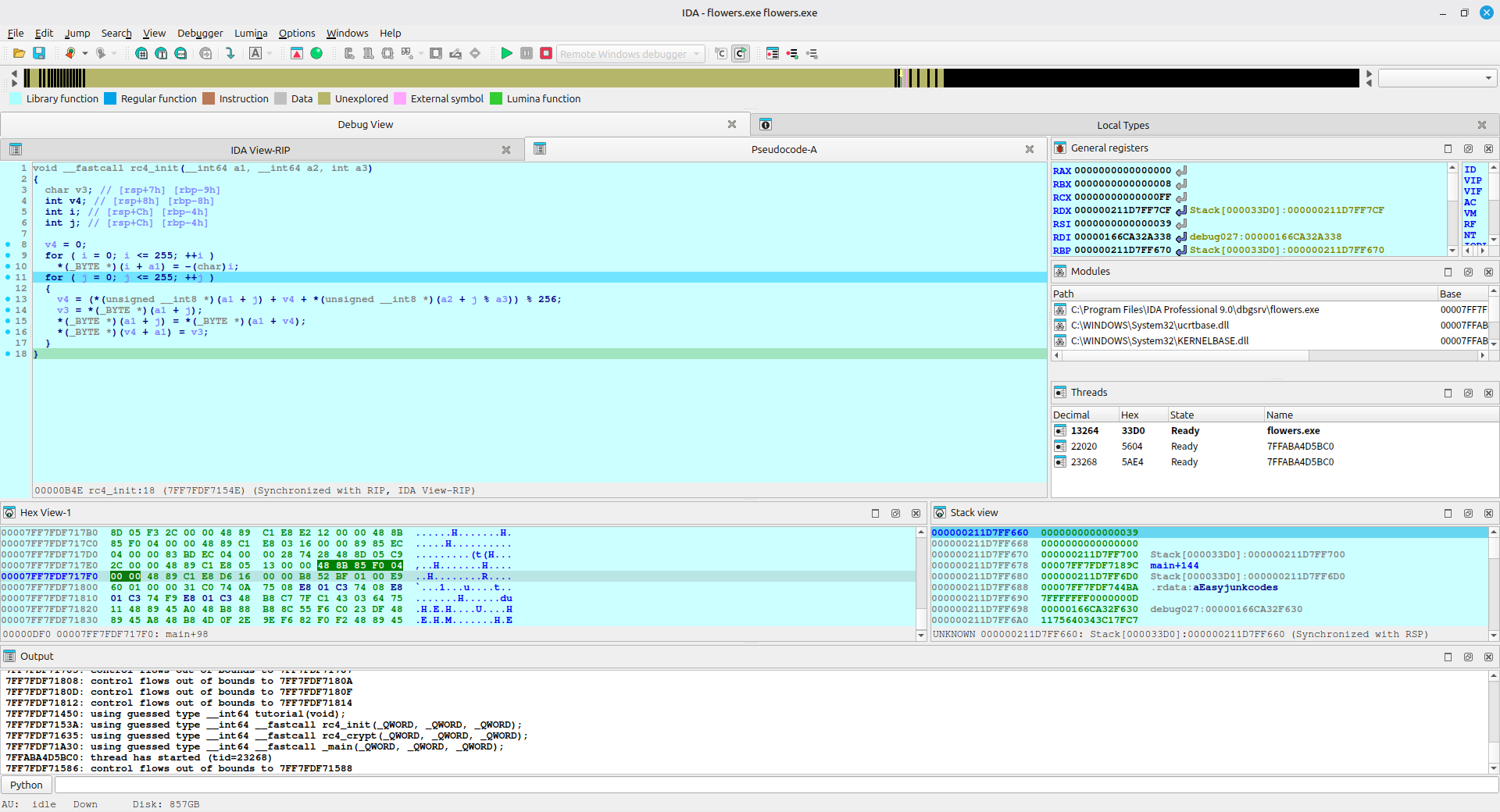
rc4_crypt 也是一样的手法
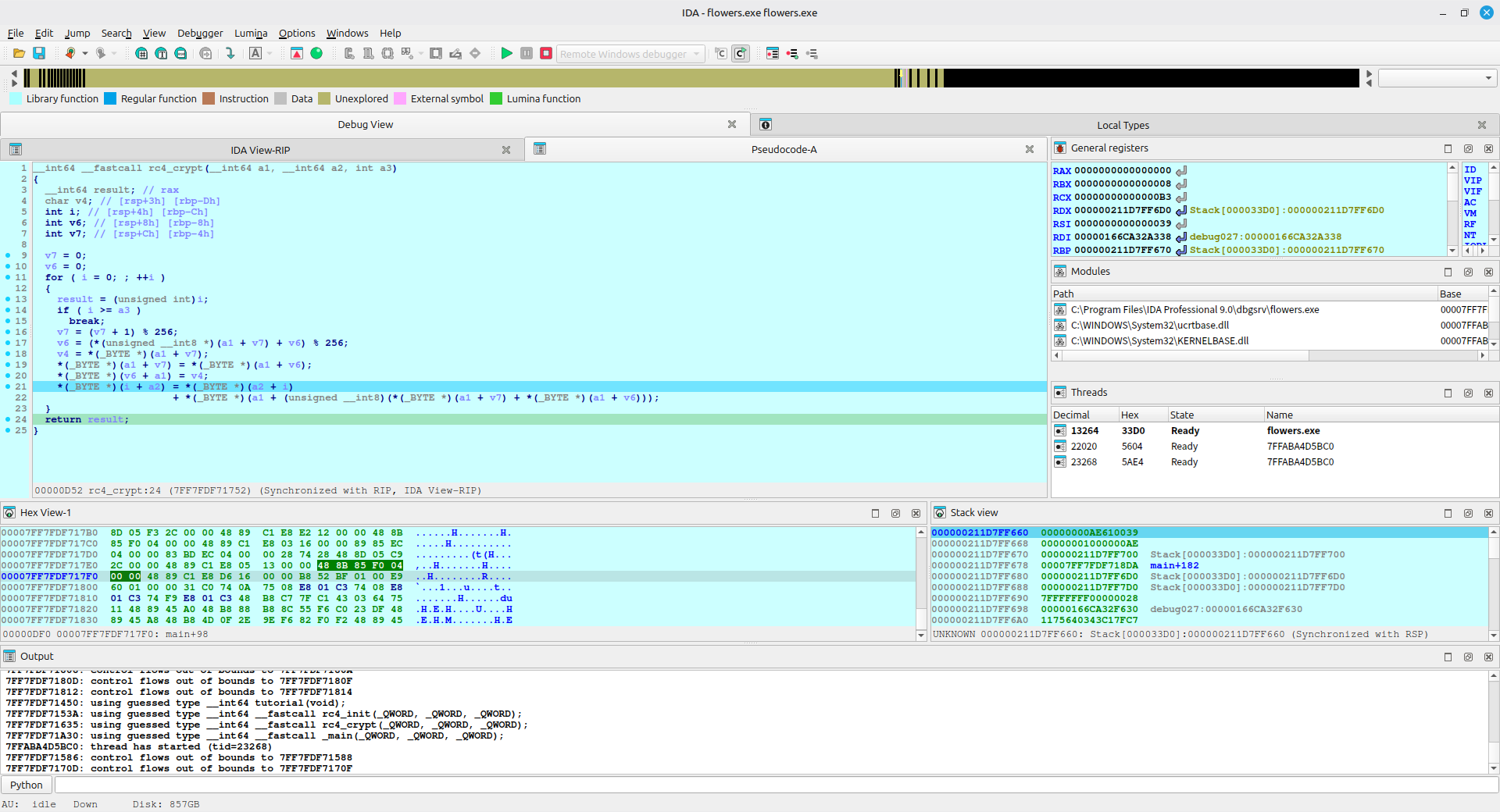
这两个函数都是魔改了 RC4 算法,有关 RC4 的部分,可以问问 AI 或者 B站上有视频讲解,这里不再赘述。
魔改的部分如下:
-
在 rc4_init 的 S 盒生成中,将标准 RC4 中的
S[i] = i改为了S[i] = -i -
而在 rc4_crypt 中,将标准 RC4 中使用的异或改成了加法,这也使得用同一个函数无法进行解密(RC4 的特性是加密函数同时是解密函数,这个特性是使用异或带来的可逆性,感兴趣的同学可以自行搜索位运算,了解他们的特性)
根据上面的内容,写出解密脚本:
# 这些是 16 进制的密文
CIPHER = [
0x1175640343C17FC7,
0xDF23C0F6558CB888,
0xF2F082F69E2E0F4D,
0xE1278329086B51BC,
0x4E4F80B188C6BDCB
]
KEY = b"EasyJunkCodes"
def signed8(x):
# 伪代码中将数强制转换为 8 位的 char 类型了,所以这里需要将数映射为 8 位
return x - 256 if x >= 128 else x
def init_S_variant(key_bytes):
S = [0]*256
for i in range(256):
S[i] = (-signed8(i)) & 0xFF # & 0xFF 是取低八位的操作
i = 0
keylen = len(key_bytes)
for j in range(256):
i = (S[j] + i + key_bytes[j % keylen]) % 256
S[j], S[i] = S[i], S[j]
return S
def prga_variant(S, length):
# 生成密钥流,RC4 的一步
i = j = 0
ks = []
for _ in range(length):
i = (i + 1) % 256
j = (S[i] + j) % 256
S[i], S[j] = S[j], S[i]
ks_byte = S[(S[i] + S[j]) & 0xFF]
ks.append(ks_byte)
return ks
def build_ciphertext():
# 用小端序拼接密文,有关端序可以在《深入理解计算机系统》(CS:APP)的 2.1.3 中了解
b = bytearray()
for q in CIPHER:
b += int(q).to_bytes(8, byteorder='little')
return bytes(b)
def decrypt():
cipher = build_ciphertext()
S = init_S_variant(list(KEY))
ks = prga_variant(S, len(cipher))
# 题目程序是加法,所以要使用加法的逆运算减法才能解密
plain = bytes((c - k) & 0xFF for c, k in zip(cipher, ks))
try:
print(plain.decode('ascii'))
except Exception:
print('error decoding as ascii')
if __name__ == "__main__":
decrypt()
OhNativeEnc
使用 JADX 打开,在 FirstFragment 类中可以发现使用了 Native 层的函数
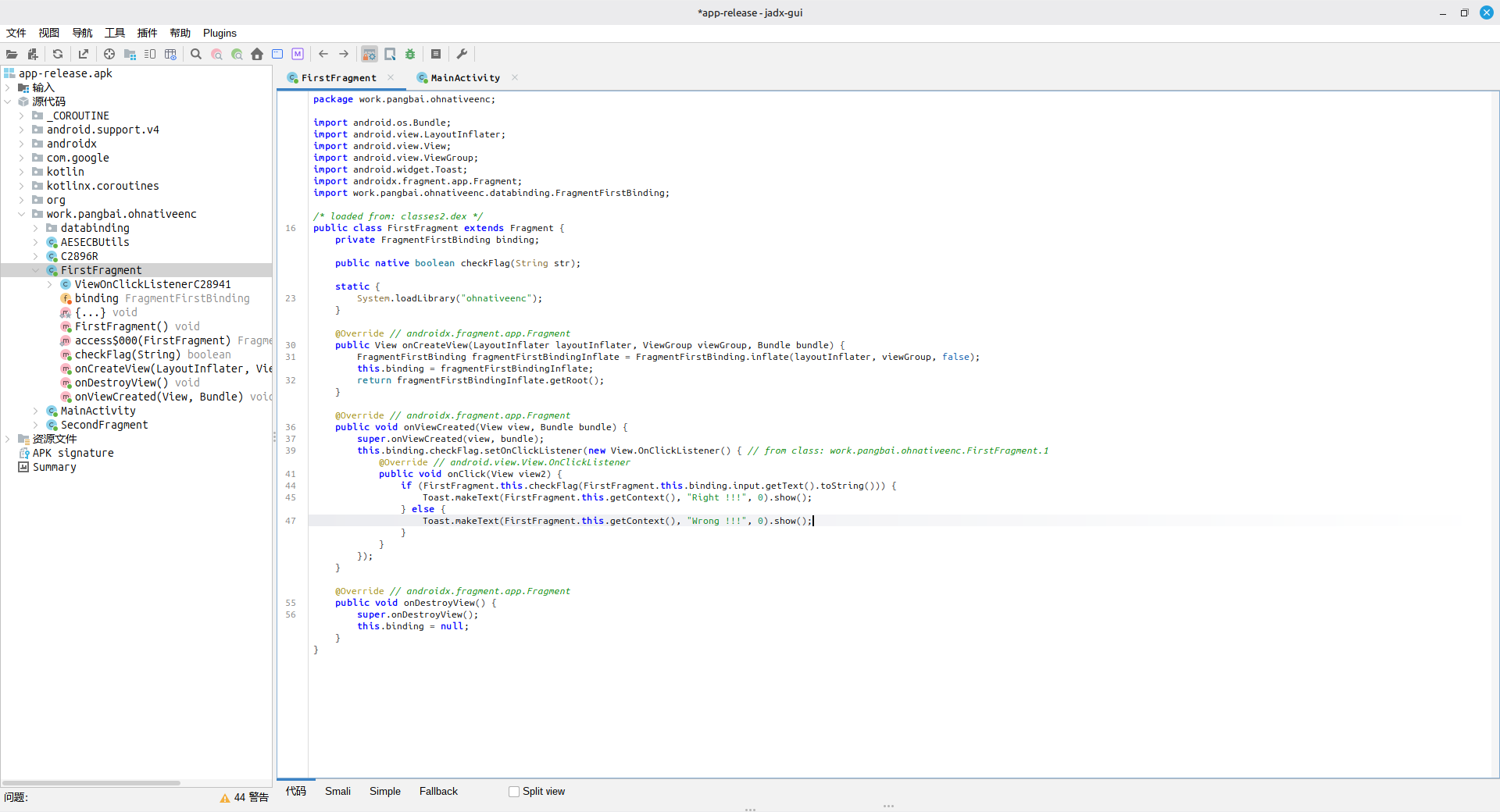
在资源文件 -> lib -> x86_64 -> libohnativeenc.so,右键导出,然后使用 IDA 打开
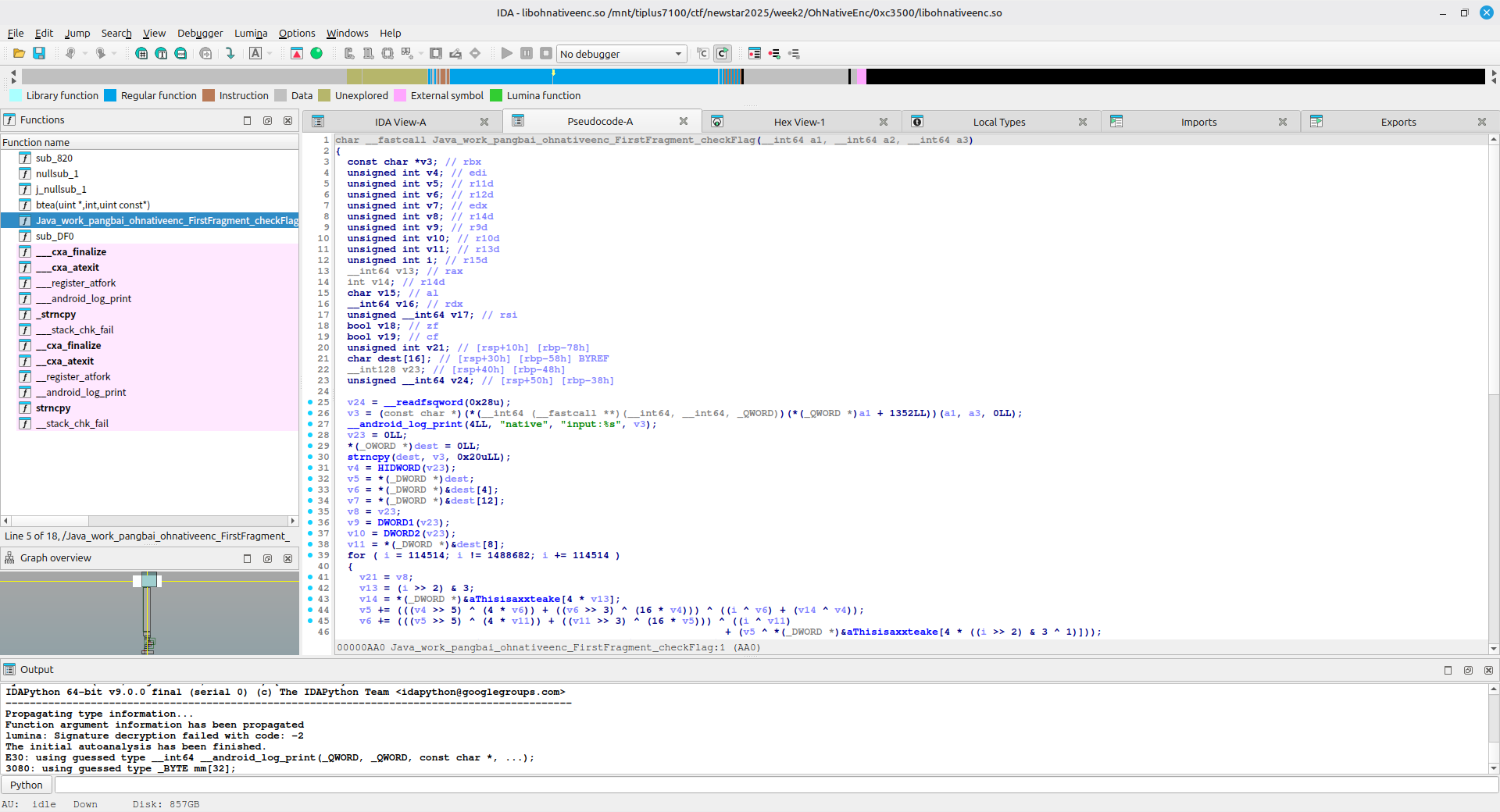
找到对应的函数,可以看到小改了 XXTEA 的 delta,将轮数固定为 12 轮
根据以上内容,可以写出解密代码:
from struct import pack, unpack
# 小端序转换
def bytes_to_words_le(b):
return list(unpack('<' + 'I'*(len(b)//4), b))
def words_to_bytes_le(w):
return pack('<' + 'I'*len(w), *[x & 0xFFFFFFFF for x in w])
def decrypt(v, k):
delta = 114514 # 魔改的 Delta
rounds = 12 # 固定轮数
mask = 0xFFFFFFFF
sum_ = (delta * rounds) & mask
while sum_ != 0:
e = (sum_ >> 2) & 3
for p in range(len(v) - 1, -1, -1): # 反向循环,XXTEA解密流程
z = v[(p - 1) % len(v)]
y = v[(p + 1) % len(v)]
mx = (((z >> 5) ^ (y << 2)) +
((y >> 3) ^ (z << 4))) ^ ((sum_ ^ y) + (k[(p & 3) ^ e] ^ z))
v[p] = (v[p] - mx) & mask
sum_ = (sum_ - delta) & mask
return v
# 密钥与密文的 16 进制
key_hex = "54 68 69 73 49 73 41 58 58 74 65 61 4B 65 79 00"
data_hex = "B6 53 6E 4D 77 5D 08 D2 FB 2C 63 1E BB 7B 01 9B F5 04 6A F4 0E 84 27 47 64 A1 E4 D9 EF 12 44 37"
k = bytes_to_words_le(bytes(int(x, 16) for x in key_hex.split()))
v = bytes_to_words_le(bytes(int(x, 16) for x in data_hex.split()))
plain = words_to_bytes_le(decrypt(v, k)).rstrip(b'\x00')
print(plain.decode('utf-8'))
Look at me carefully
先用 IDA 打开,可以发现重复调用了很多遍一样的函数
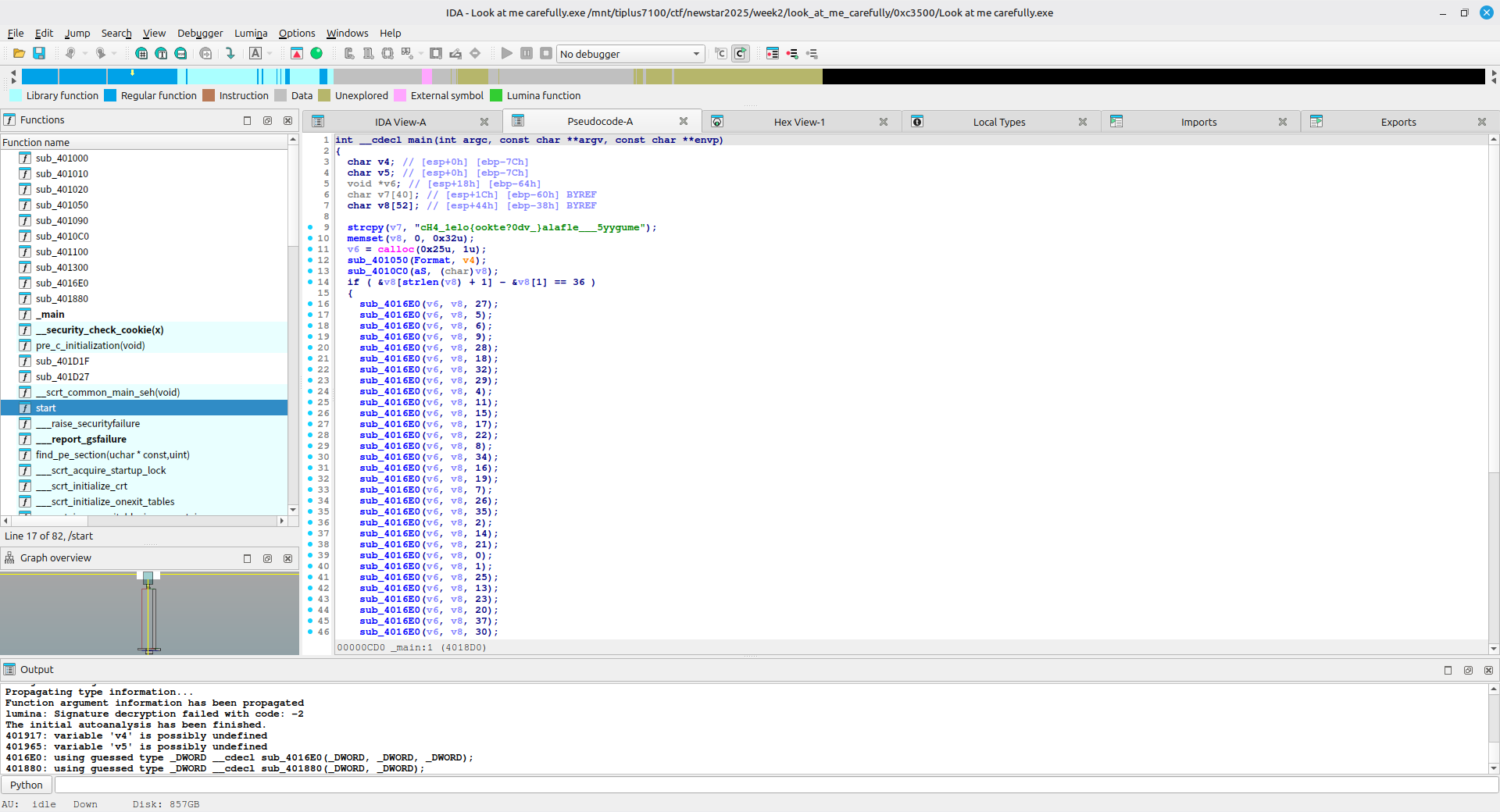
查看这个函数的内部
其中,sub_401300 函数并没有对两个字符串做出任何更改

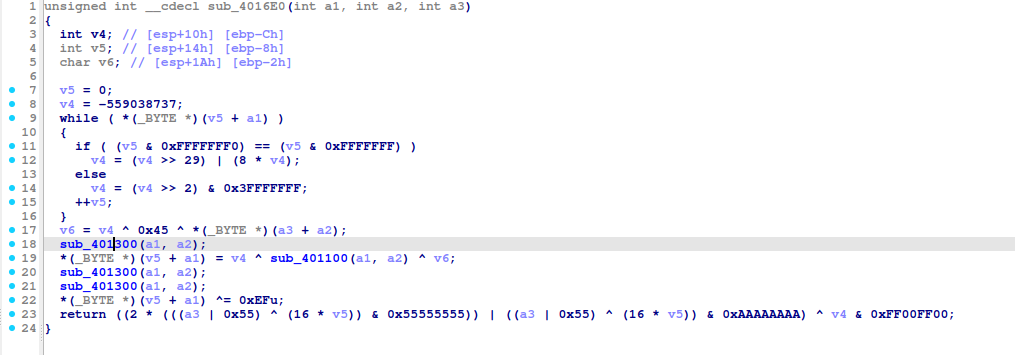
v4 变更后选择的 switch 的分支总是 case 4 ,而 case 4 里没有对两个字符串做出任何更改
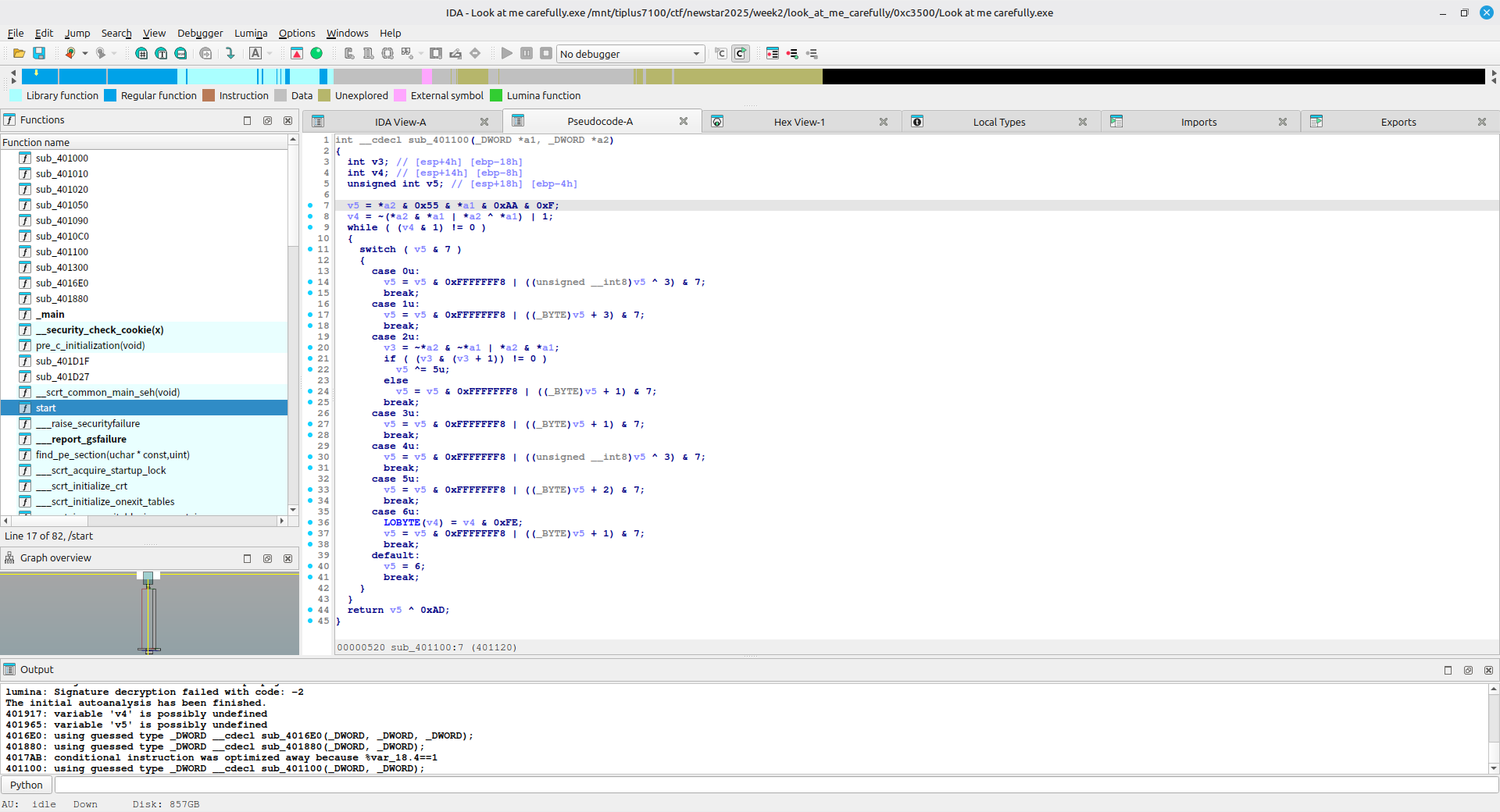
sub_401100 函数中,因为 0x55 & 0xAA = 0,而任何数和 0 按位和总是等于零,所以 v5 为零,这样就只会进入 case 0 分支了,v5 变为 3,进入 case 3 分支,v5 变为 4,进入 case 4 分支,v5 变为 7,进入 default 分支,v5 变为 6,进入 case 6 分支,早前 v4 的最低位因最后与 1 按位或,所以最后一位为 1,现在与 0xFE 按位与,而 0xFE 最后一位为 0,所以 v4 最后一位也为 0 ,与只有一位的 1 按位和肯定为 0 ,所以这个分支执行完循环就会终止,而最终 v5 会变为 7,函数的返回值则为 170
静态分析很复杂,有非常多的位运算,但其实只需要动调就可以看最后 v5 是什么值了
在返回处下断点,运行到此处会暂停
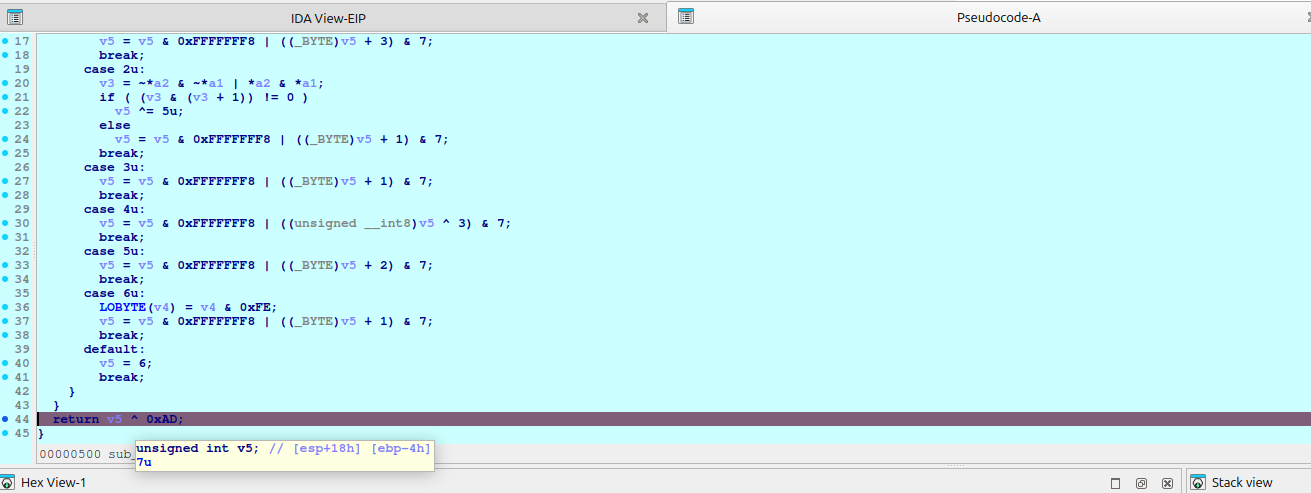
光标放在变量上就可以查看变量值了
回到 sub_1A16E0 可以发现,程序的逻辑不过是将对应第 a3 位的字符分别与170、0xEF、0x45异或后,按顺序依次放在密文中
而 170 ^ 0xEF ^ 0x45 = 0,任何数和 0 异或都为其本身,所以程序的逻辑就是将对应第 a3 位的字符按顺序依次放在密文中
由此可以写出解密脚本:
ciphertext = 'cH4_1elo{ookte?0dv_}alafle___5yygume'
plaintext = [None] * 38
index_list = [27, 5, 6, 9, 28, 18, 32, 29, 4, 11, 15, 17, 22, 8, 34, 16, 19, 7, 26, 35, 2, 14, 21, 0, 1, 25, 13, 23, 20, 30, 33, 10, 3, 12, 24, 31]
for i in range(36):
plaintext[index_list[i]] = ciphertext[i]
for i in range(36):
print(plaintext[i], end='')
尤皮·埃克斯历险记(1)
这题需要用到除了 IDA 以外的东西了
使用 DIE(Detect It Easy) 来打开,查看程序属性,这步也叫查壳
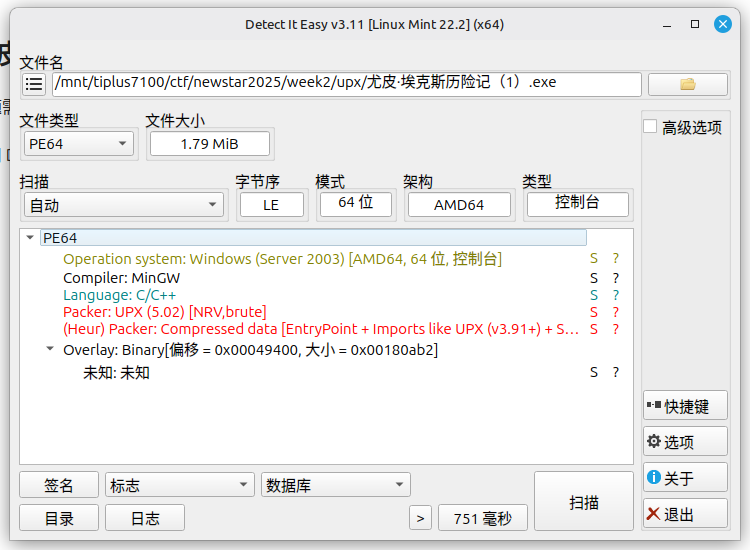
可以发现使用了 UPX 壳
有关壳和 UPX 壳看下面的文章:
加了 UPX 壳的程序直接使用 IDA 打开函数会特别少,这是 UPX 壳的特征之一
UPX 壳去除也相对简单,使用工具即可
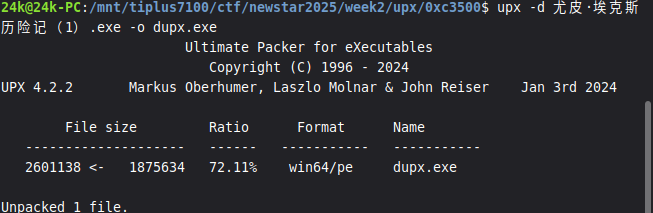
再用 IDA 打开就是正常的程序逻辑了
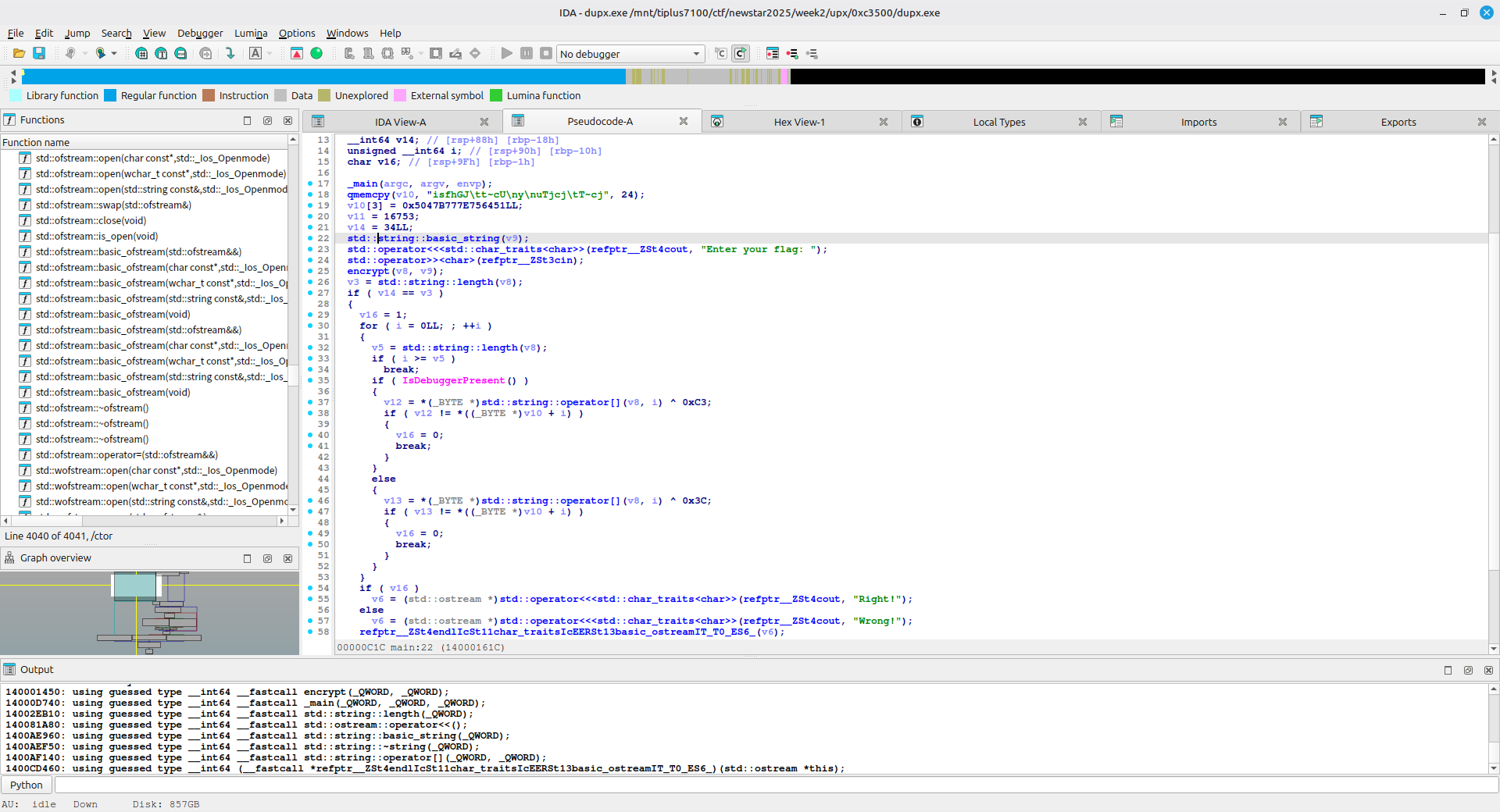
encrypt 函数如下:
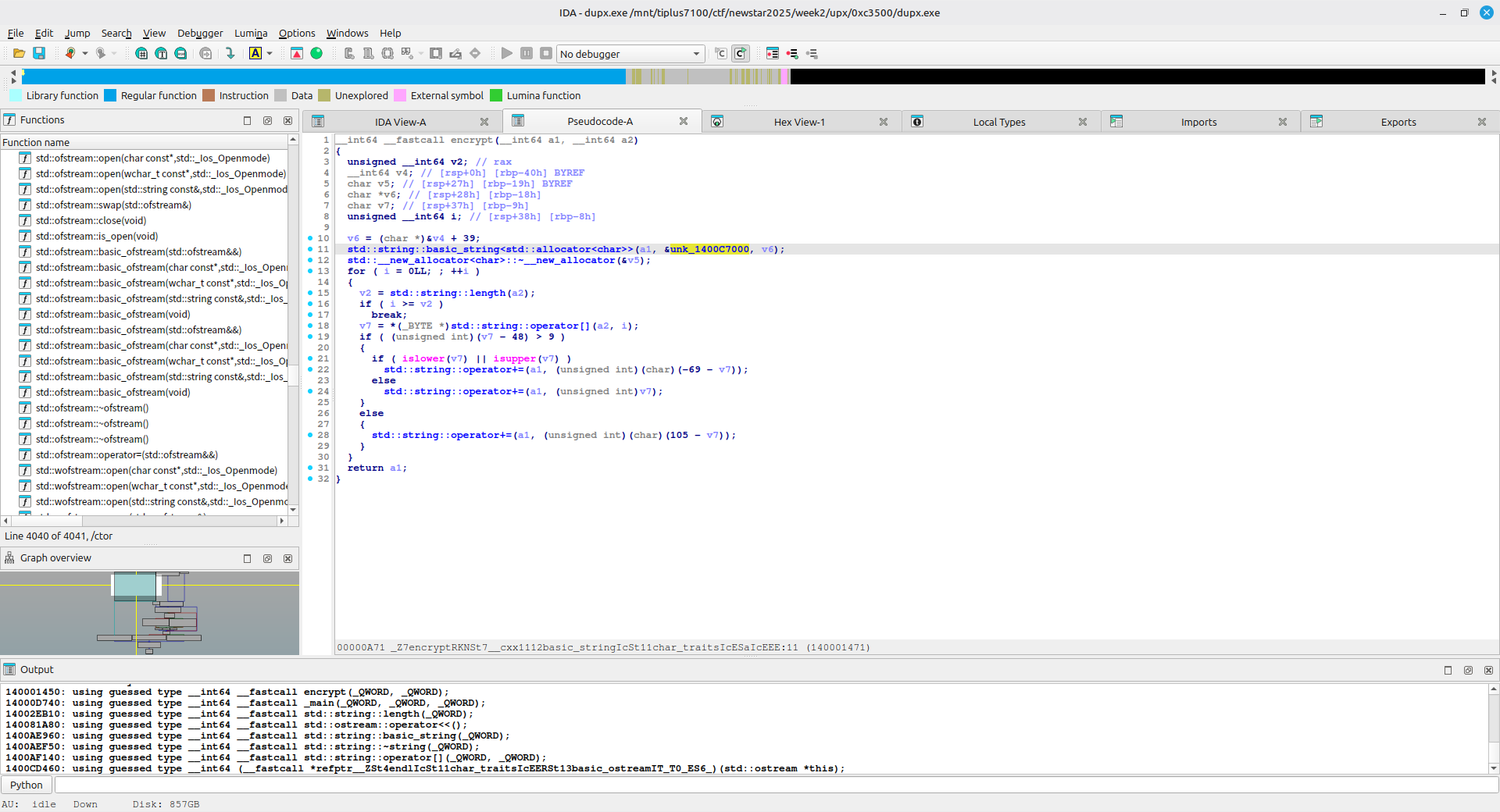
根据 main 函数和 encrypt 函数的逻辑,可以写出解密脚本:
a = "isfhGJ\tt~cU\ny\nuTjcj\tT~cjQdu~w{\x04\x05qA"
for i in a:
ii = ord(i) ^ 0x3c
if 65 <= 187 - ii <= 90 or 97 <= 187 - ii <= 122:
print(chr(187 - ii), end="")
elif 48 <= 105 - ii <= 57:
print(chr(105 - ii), end="")
else:
print(chr(ii), end="")
Forgotten_Code
附件是一个 .s 文件,是编译的一个中间阶段:由源代码生成汇编
关于编译的过程可以上网了解,此处不再赘述
Windows 环境下,安装 MinGW-w64,用以下指令生成最终的二进制可执行文件:
x86_64-w64-mingw32-gcc chal.s -o chal.exe
将二进制文件使用 IDA 打开
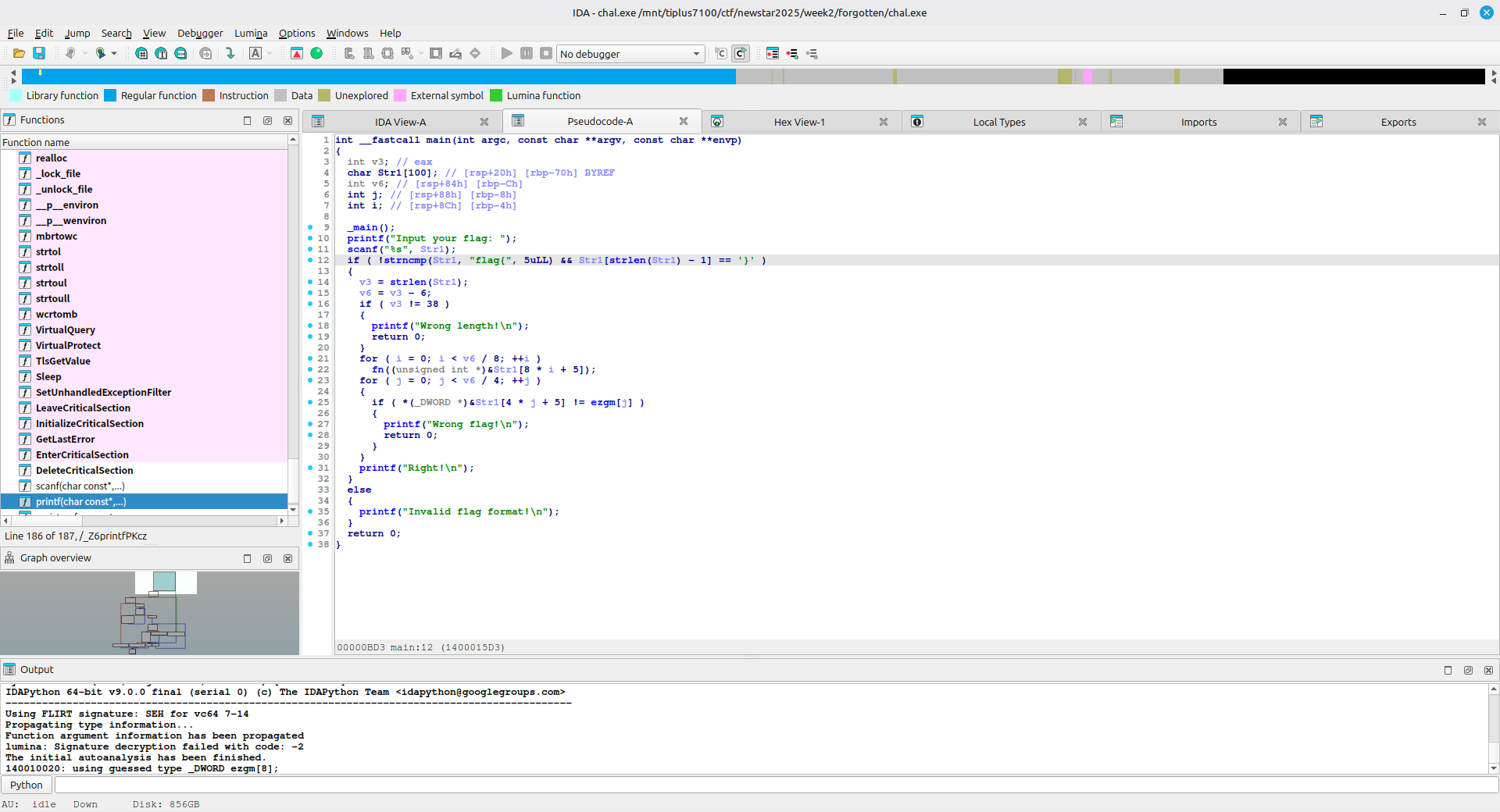
这个程序先判断 flag 是否符合格式,然后检查长度,使用 fn 函数加密,最后与 ezgm 数组对比
查看 fn 函数内容
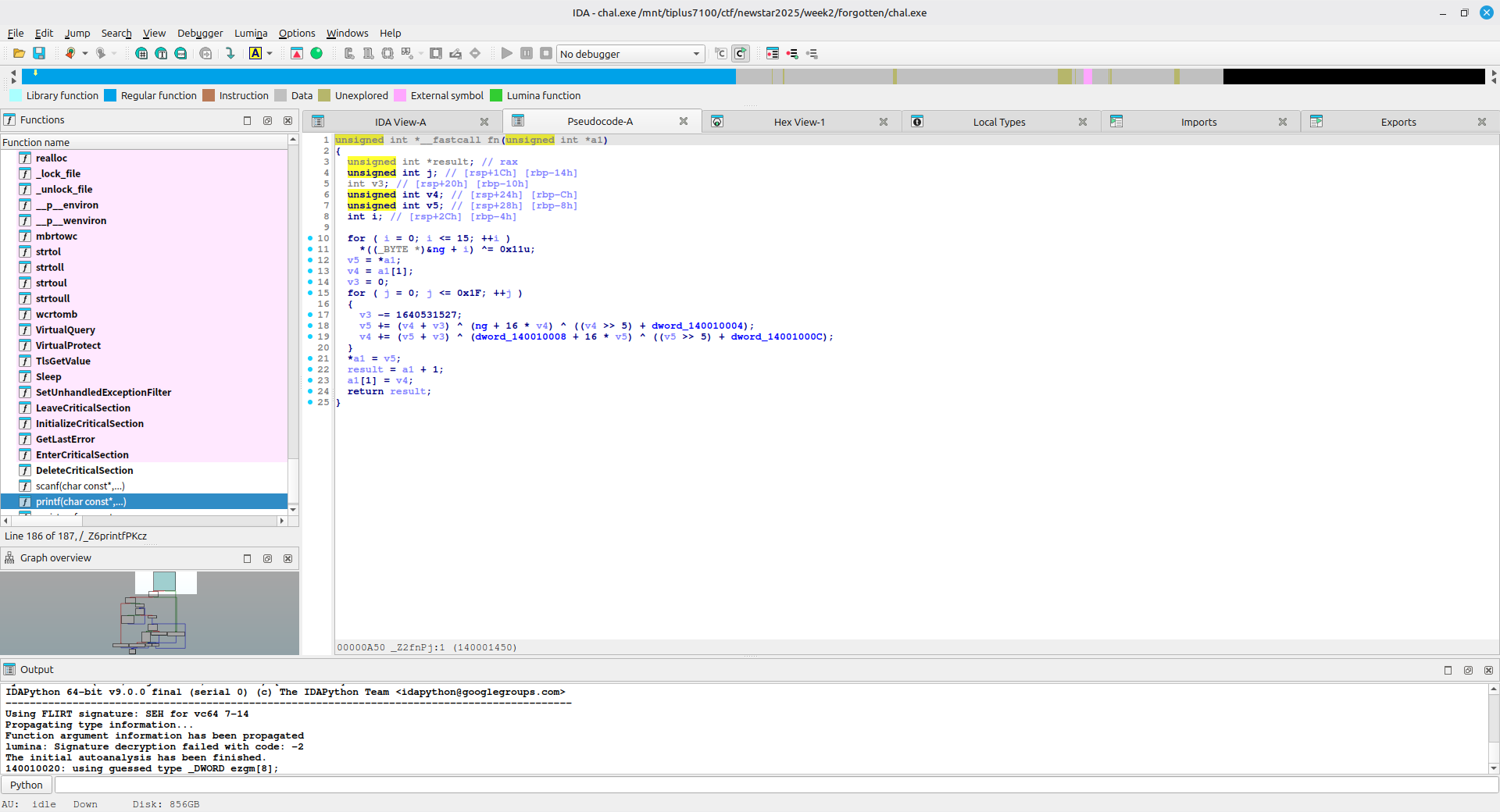
题目稍微魔改了 TEA ,将左移改为了加上 16 倍的两部分,还有密钥硬编码
由此可以写出解密脚本:
#!/usr/bin/env python3
import struct
def u32(x): return x & 0xFFFFFFFF
def bytes_to_u32_le(b): return struct.unpack("<I", b)[0]
def u32_to_bytes_le(x): return struct.pack("<I", u32(x))
ezgm = [
1210405119,
710975774,
-90350153,
-1958008304,
-745722482,
67707510,
-86515270,
-1728462407
]
ezgm_u32 = [x & 0xFFFFFFFF for x in ezgm]
ng_bytes = b"sp\x7fvuctp|xeb|hv~"
# 分块,八字节一组
blocks = []
for i in range(0, 8, 2):
lo = ezgm_u32[i]
hi = ezgm_u32[i+1]
blocks.append(u32_to_bytes_le(lo) + u32_to_bytes_le(hi))
# 密钥先异或 0x11
ng_words = [bytes_to_u32_le(ng_bytes[i*4:(i+1)*4]) for i in range(4)]
ng_xor = bytes([b ^ 0x11 for b in ng_bytes])
ng_xor_words = [bytes_to_u32_le(ng_xor[i*4:(i+1)*4]) for i in range(4)]
keys = [ng_xor_words, ng_words, ng_xor_words, ng_words]
def tea_decrypt_block(block8, key_words):
v0 = bytes_to_u32_le(block8[:4])
v1 = bytes_to_u32_le(block8[4:])
k0, k1, k2, k3 = key_words
delta = 0x9E3779B9
sum_ = u32(delta * 32)
for _ in range(32):
v1 = u32(v1 - ( ((v0<<4) + k2) ^ (v0 + sum_) ^ ((v0>>5) + k3) ))
v0 = u32(v0 - ( ((v1<<4) + k0) ^ (v1 + sum_) ^ ((v1>>5) + k1) ))
sum_ = u32(sum_ - delta)
return u32_to_bytes_le(v0) + u32_to_bytes_le(v1)
plaintext_blocks = [tea_decrypt_block(blocks[i], keys[i]) for i in range(4)]
flag_inner = b"".join(plaintext_blocks)
flag = b"flag{" + flag_inner + b"}"
print(flag.decode('ascii'))